
When Dimitris Papailiopoulos first asked ChatGPT to interpret colors in images, he was thinking about “the dress”—the notoriously confusing optical-illusion photograph that took the Internet by storm in 2015. Papailiopoulos, an associate professor of computer engineering at the University of Wisconsin–Madison, studies the type of artificial intelligence that underlies chatbots such as OpenAI’s ChatGPT and Google’s Gemini. He was curious about how these AI models might respond to illusions that trick the human brain.
The human visual system is adapted to perceive objects as having consistent colors so that we can still recognize items in different lighting conditions. To our eyes, a leaf looks green in bright midday and in an orange sunset—even though the leaf reflects different light wavelengths as the day progresses. This adaptation has given our brain all sorts of nifty ways to see false colors, and many of these lead to familiar optical illusions, such as checkerboards that seem consistently patterned (but aren’t) when shadowed by cylinders—or objects such as Coca-Cola cans that falsely appear in their familiar colors when layered with distorting stripes.
In a series of tests, Papailiopoulos observed that GPT-4V (a recent version of ChatGPT) seems to fall for many the same visual deceptions that fool people. The chatbot’s answers often match human perception—by not identifying the actual color of the pixels in an image but describing the same color that a person likely would. That was even true with photographs that Papailiopoulos created, such as one of sashimi that still looks pink despite a blue filter. This particular image, an example of what’s known as a color-constancy illusion, hadn’t previously been posted online and therefore could not have been included in any AI chatbot’s training data.
On supporting science journalism
If you're enjoying this article, consider supporting our award-winning journalism by subscribing. By purchasing a subscription you are helping to ensure the future of impactful stories about the discoveries and ideas shaping our world today.

A picture of a target (left) and a blue-filtered image that shows the color-constancy illusion (right). Although the bull’s-eye in the manipulated version appears red, in fact, its pixels have greater blue and green values. (The blue filter was applied using a tool created by Akiyoshi Kitaoka.)
krisanapong detraphiphat/Getty Images (photograph); Akiyoshi Kitaoka's histogram compression (blue filter)
“This was not a scientific study,” Papailiopoulos notes—just some casual experimentation. But he says that the chatbot’s surprisingly humanlike responses don’t have clear explanations. At first, he wondered whether ChatGPT cleans raw images to make the data it processes more uniform. OpenAI told Scientific American in an e-mail, however, that ChatGPT does not fine-tune the color temperature or other features of an input image before GPT-4V interprets it. Without that straightforward explanation, Papailiopoulos says it’s possible that the vision-language transformer model has learned to interpret color in context, assessing the objects within an image in comparison to each other and evaluating pixels accordingly, similar to what the human brain does.
Blake Richards, an associate professor of computer science and neuroscience at McGill University, agrees the model could have learned color contextually like humans do, identifying an object and responding to how that type of item generally appears. In the case of “the dress,” for instance, scientists think that different people interpreted the colors in two disparate ways (as gold and white or blue and black) based on their assumptions about the light source illuminating the fabric.
The fact that an AI model can interpret images in a similarly nuanced way informs our understanding of how people likely develop the same skill set, Richards says. “It tells us that our own tendency to do this is almost surely the result of simple exposure to data,” he explains. If an algorithm fed lots of training data begins to interpret color subjectively, it means that human and machine perception may be closely aligned—at least in this one regard.
Yet in other instances, as recent studies show, these models don’t behave like us at all—a fact that reveals key differences between how people and machines “see” the world. Some researchers have found that newly developed vision-language transformer models respond to illusions inconsistently. Sometimes they respond as humans would; in other cases, they provide purely logical and objectively accurate responses. And occasionally they answer with total nonsense, likely the result of hallucination.
The motivation behind such studies isn’t to prove that humans and AI are alike. One fundamental difference is that our brain is full of nonlinear connections and feedback loops that ferry signals back and forth. As our eyes and other sensory systems collect information from the outside world, these iterative networks “help our brains fill in any gaps,” says Joel Zylberberg, a computational neuroscientist at York University in Ontario, who wasn’t involved in the optical illusion studies. Though some recurrent neural networks have been developed to mimic this aspect of the human brain, many machine-learning models aren’t designed to have repetitive, two-directional connections. The most popular generative transformer AI models rely on mathematical functions that are “feed-forward.” This means information moves through them in only one direction: from input toward output.
Studying how such AI systems react to optical illusions could help computer scientists better understand the abilities and biases of these one-way machine-learning models. It could help AI researchers home in on what factors beyond recurrence are relevant for mimicking human responses.
One potential factor is a model’s size, according to a team of computer scientists who assessed four open-source vision-language models and presented its findings at a December 2023 conference. The researchers found that larger models, meaning those developed with more weights and variables that determine a response, were more closely aligned with human responses to optical illusions than smaller ones. Overall, the AI models the scientists tested were not particularly good at homing in on illusory elements within an image (they were less than 36 percent accurate on average) and only aligned with human responses in about 16 percent of cases on average. Yet the study also found models mimicked humans more closely in response to certain types of illusions than others.
Asking these models to evaluate perspective illusions, for example, yielded the most humanlike outputs. In perspective illusions, equally sized objects within an image appear to have different sizes when placed against a background that suggests three-dimensional depth. Models were asked to judge the relative size of the silhouette of objects in an image—and the researchers also repeated this test with paired and flipped images to detect any potential right- or left-side bias in the models’ responses. If the bot’s responses to all questions matched the standard human perception, the study authors considered it “humanlike.” For one type of prompt, which measured the models’ ability to locate objects in an image, the two models tested were up to 75 percent humanlike in responding to perspective illusions. In other tests and for other models, the rates of humanlike responses were considerably lower.
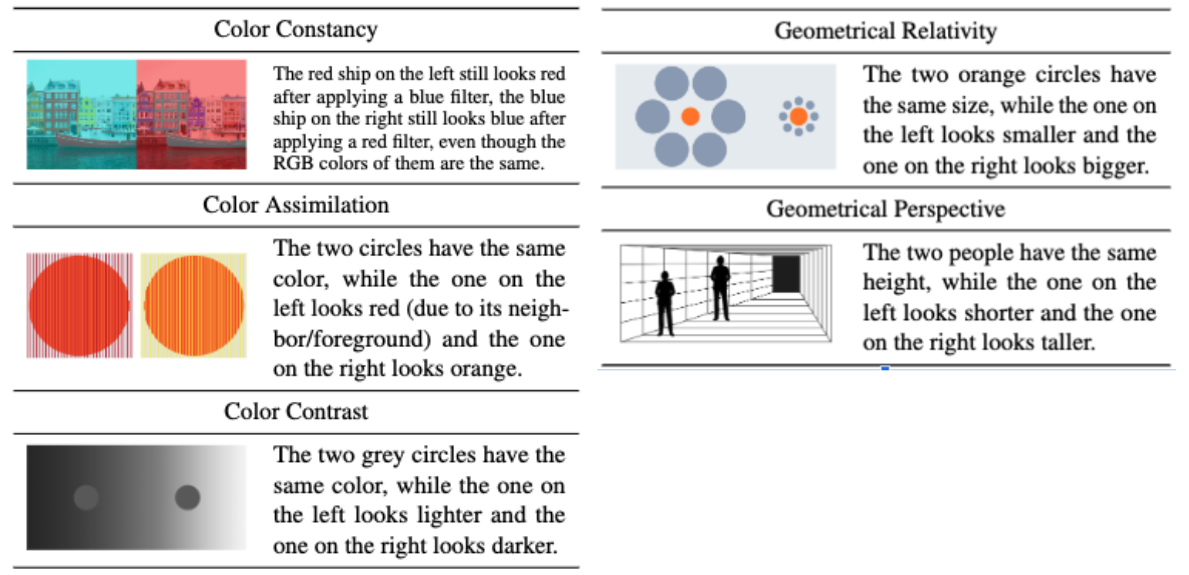{kind=link}
In a separate preprint study released in March, researchers tested the abilities of GPT-4V and Google’s Gemini-Pro to evaluate 12 different categories of optical illusions. Those included impossible-object illusions, which are two-dimensional figures of objects that could not exist in three-dimensional space, and hidden-image illusions in which silhouettes of objects are included in an image without being immediately obvious. In nine out of 12 of the categories, the models were worse at pinpointing what was happening in an illusion compared with people, averaging 59 percent accuracy versus human respondents’ 94 percent. But in three categories—color, angle and size illusions—GPT-4V performed comparably or even slightly better than human reviewers.
Wasi Ahmad, one of the study authors and an applied scientist in Amazon Web Services’ AI lab, thinks the difference comes down to whether analyzing the illusions requires quantitative or qualitative reasoning. Humans are adept at both. Machine-learning models, on the other hand, might be less poised to make judgments based on things that can’t be easily measured, Ahmad says. All three of the illusion categories where the AI systems were best at interpreting involve quantifiably measurable attributes, not just subjective perception.
To deploy AI systems responsibly, we need to understand their vulnerabilities and blind spots as well as where human tendencies will and won’t be replicated, says Joyce Chai, a computer science professor and AI researcher at University of Michigan and senior author of the preprint presented at the December 2023 conference. “It could be good or bad for a model to align with humans,” she says. In some cases, it’s desirable for a model to mitigate human biases. AI medical diagnostic tools that analyze radiology images, for instance, would ideally not be susceptible to visual error.
In other applications, though, it might be beneficial for an AI to mimic certain human biases. We may want the AI visual systems used in self-driving cars to match human error, Richards points out, so that vehicle mistakes are easier to predict and understand. “One of the biggest dangers with self-driving cars is not that they’ll make mistakes. Humans make mistakes driving all the time,” he says. But what concerns him about autonomous vehicles are their “weird errors,” which established safety systems on the road aren’t prepared to handle.
OpenAI’s GPT-4V and other large machine-learning models are often described as black boxes—opaque systems that provide outputs without explanation—but the very human phenomenon of optical illusions could offer a glimpse of what’s inside them.